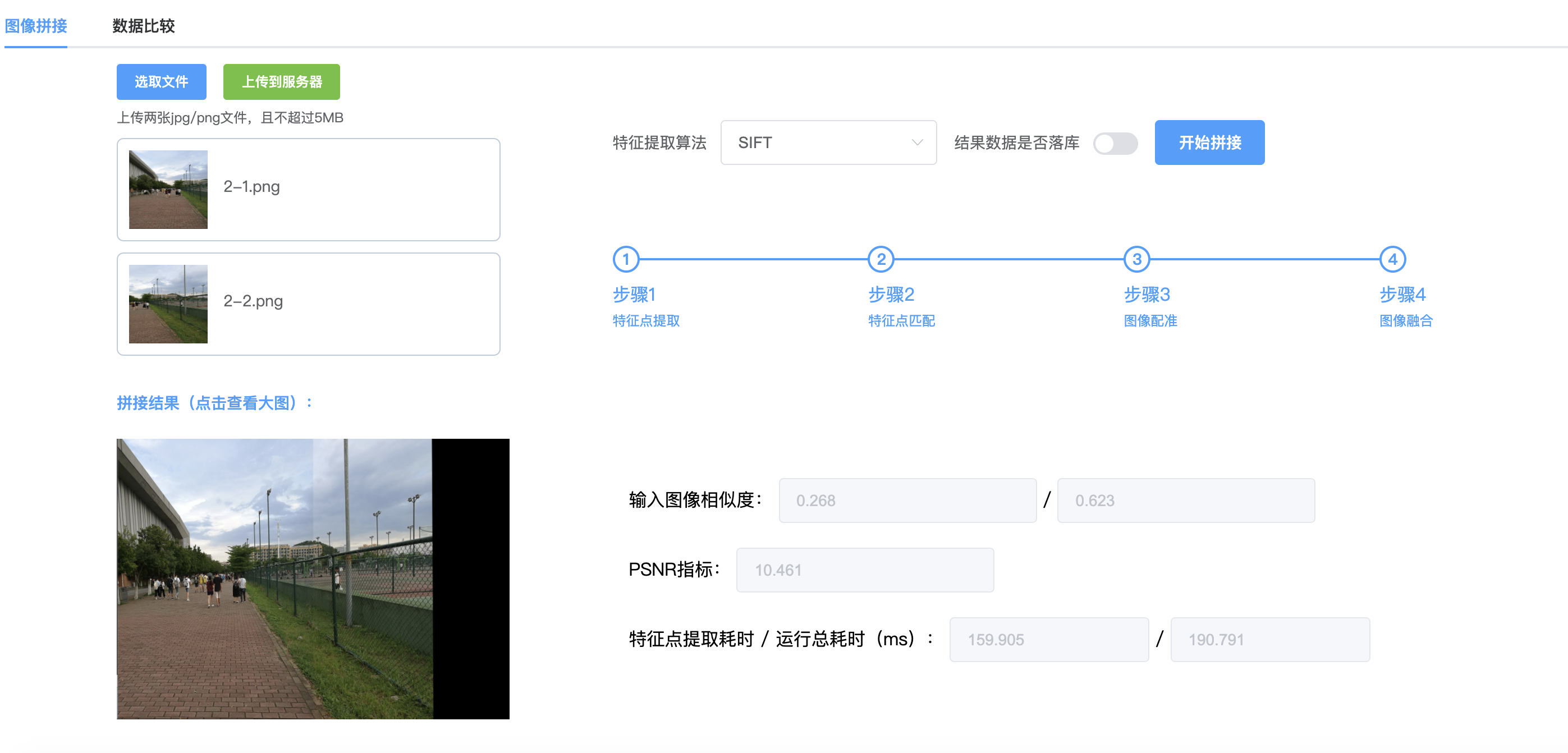
dataTree a = Nil | Node a (Treea) (Treea) deriving (Show, Eq) invert :: Tree a -> Tree a invertNil = Nil invert (Node v l r) = Node v (invert r) (invert l)
虚拟机在堆内存中为该对象实例划分内存空间,这里有两种,一种是连续内存,连续内存里一段是已经使用的内存,一段是空闲内存,之间由一个指针指向分界点,这种划分内存就是让这个指针向空闲内存偏移一段地址,称为指针碰撞,另一种是非连续的内存,这种就需要维护一个list,记录哪段内存被占用了哪段没有,这种分配方法称为空闲列表。在这一个阶段中,假如是并发状态,分配空间的操作不一定是线程安全的,这时也有两种方案,一种是CAS加锁,另一种是让每个线程在虚拟机中预先分配一块内存,称为本地线程分配缓冲(Thread Local Allocation Buffer, TLAB)
if (w <= 0 || h <= 0 || w * (int64_t)h >= INT_MAX / 3 || 2LL * w + 12 >= INT_MAX / sizeof(*temp)) { fprintf(stderr, "Dimensions are too large, or invalid\n"); return-2; }
floatssim_plane( pixel *pix1, intptr_t stride1, pixel *pix2, intptr_t stride2, intwidth, intheight, void *buf, int *cnt) { int z = 0; int x, y; float ssim = 0.0; int(*sum0)[4] = (int(*)[4])buf; int(*sum1)[4] = sum0 + (width >> 2) + 3; width >>= 2; height >>= 2; for (y = 1; y < height; y++) { for (; z <= y; z++) { // FFSWAP( (int (*)[4]), sum0, sum1 ); int(*tmp)[4] = sum0; sum0 = sum1; sum1 = tmp;
for (x = 0; x < width; x += 2) ssim_4x4x2_core(&pix1[4 * (x + z * stride1)], stride1, &pix2[4 * (x + z * stride2)], stride2, &sum0[x]); } for (x = 0; x < width - 1; x += 4) ssim += ssim_end4(sum0 + x, sum1 + x, FFMIN(4, width - x - 1)); } // *cnt = (height-1) * (width-1); return ssim / ((height - 1) * (width - 1)); }
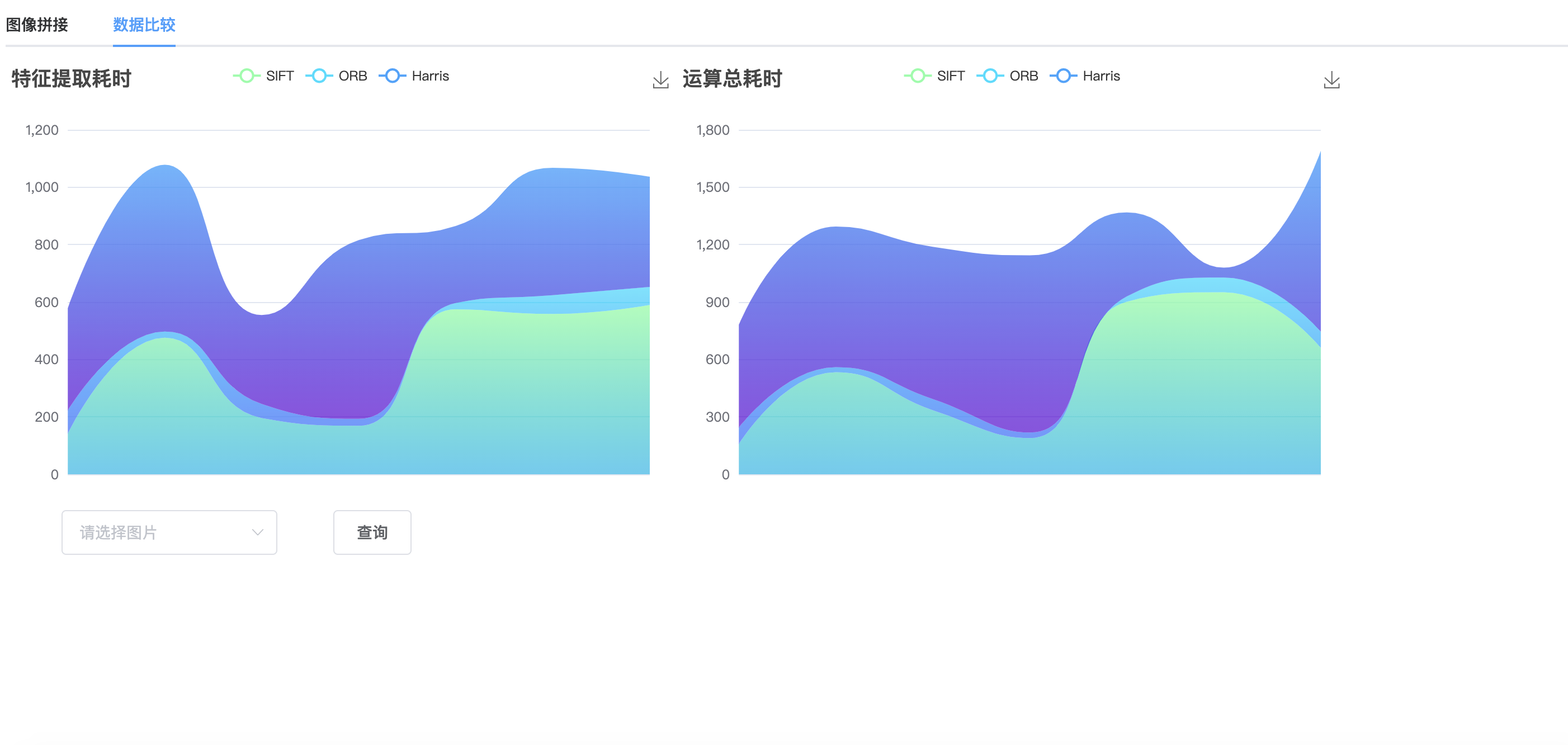
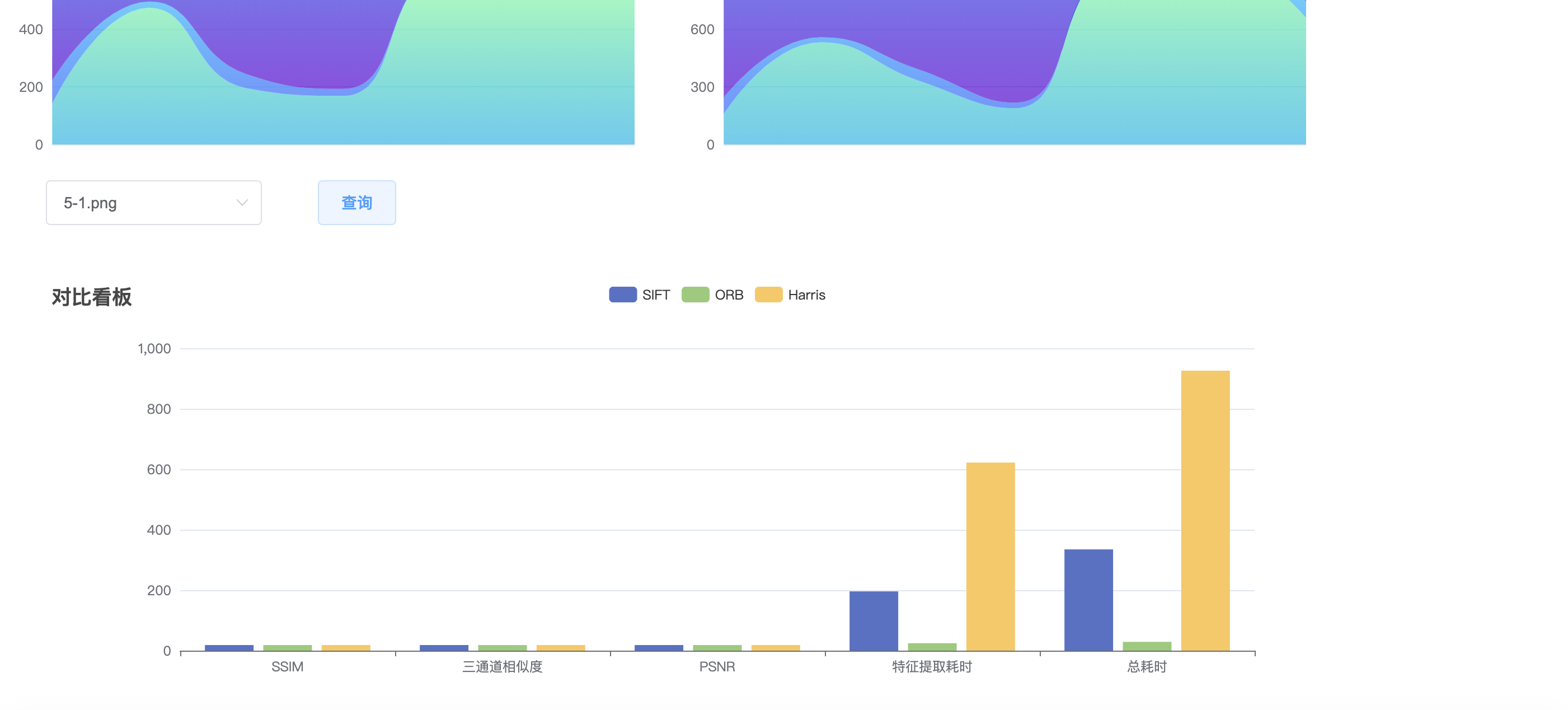
上文调用它的语句是ssim_one[i] = ssim_plane(plane[0][i], w >> !!i, plane[1][i], w >> !!i, w >> !!i, h >> !!i, temp, NULL);对于U和V向量来说,他们的内存占比是四分之一w*h,那么在填写width和height参数的时候就要分别取w和h的二分之一。
然后看ssim_plane函数体,这个函数是按照4x4的块对像素进行处理的,使用sum1保存上一行块的“信息”,sum0保存当前一行块的“信息”。sum0、sum1是一个数组指针,其中存储了一个4元素数组的地址,换句话说,sum0、sum1中每一个元素对应一个4x4块的信息(该信息包含4个元素)。4个元素中,[0]代表原始像素之和,[1]代表重建像素之和,[2]代表原始像素平方之和+重建像素平方之和,[3]代表原始像素*重建像素的值的和。然后width和height分别右移两位(÷4),因为这一步的计算是以44的像素块为基本单位的。然后进入循环,看到这句话,for (; z <= y; z++)在这个函数开头,定义了z=0,也就意味着这个循环体里的语句在第一次执行时会执行两次,其他时候就会执行一次(妙啊),为什么要执行两次呢?因为sum0存储的是一行里4x4块的信息,sum1里存着上一行里的4x4块的信息,在下文的ssim_4x4x2_core运算中,是要将这两行合起来,计算*有重叠8x8像素块的信息。在这一步循环中for (x = 0; x < width; x += 2),x每次加2,也就是每次前进两个像素,然后在ssim_4x4x2_core中计算两个4x4的像素块,也就是说,在一行中,这些4x4的像素块都是两两重叠的。
接下来进入这个循环:for (x = 0; x < width - 1; x += 4),x每次+4,步长为4,每次跳过4*4个int,进入ssim_end4:
1 2 3 4 5 6 7 8 9 10 11 12
staticfloatssim_end4(int sum0[5][4], int sum1[5][4], intwidth) { float ssim = 0.0; int i;
ssim_4x4x2_core里的sums和ssim_end4里的sum意义并不完全相同,和ssim_plane里的sum意义也不相同。sum0和sum1是一个int[*][4],也就是指向int[4]数组的指针,C/C++里,二位数组在传参的时候,第一个维度是可以不写的(写是为了起提示作用),也就是说,ssim_4x4x2_core里的int sums[2][4]和ssim_end4里的int sum0[5][4], int sum1[5][4]在数据类型上并没有什么不同,都是int[*][4],在for语句中,循环变量x第一次+2,第二次+4,因为x变了,指针的首地址也就变了,所以每次在ssim_4x4x2_core里计算的sums虽然看似每次都是计算sums[0~1][0~3],实际上每次计算的都是不同的4x4块的信息。理解了这个,对应的ssim_end4里的变量sum0/sum1也就可以理解了。
但这个计算方法明显是有问题的,例如两张图片假如只是亮度不同,MSE可能很大,而一张模糊处理后的图与原图,可能MSE就很小。于是有人在Image Quality Assessment: From Error Visibility to Structural Similarity这篇论文里提出了SSIM算法。
回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。简单来说,就是将一个方法对象 a 传递给另一个方法对象 b,让后者在适当的时候执行 a。