基本概念
OOM
OutOfMemory,Android平台上主要有三类:Java OOM,虚拟内存OOM,物理内存OOM,Java OOM指Java堆内存耗尽。
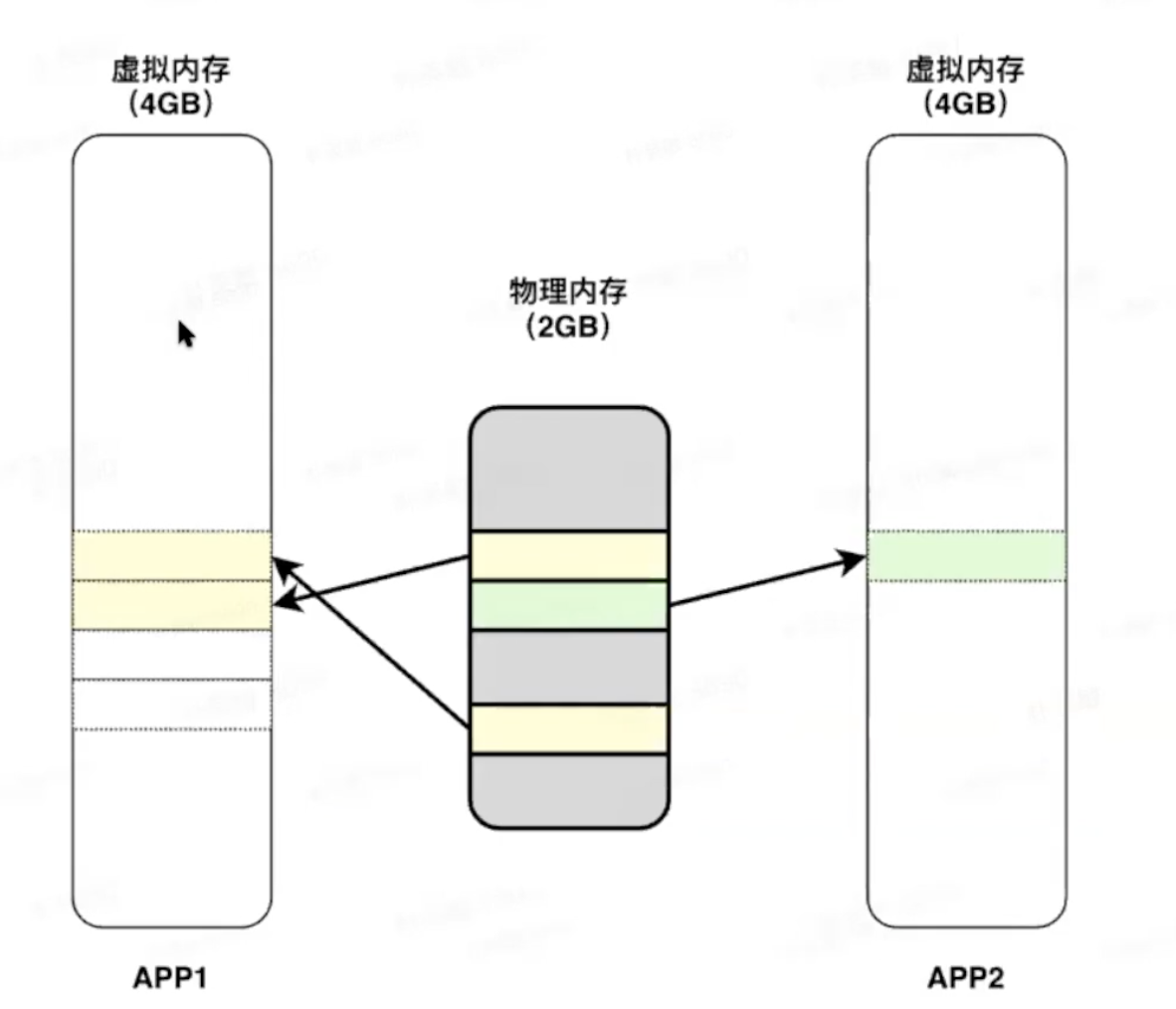
物理内存即RAM,虚拟内存主要是为了满足操作系统和应用程序对物理内存的需求。虚拟内存有几个重要特点,第一个是按需分配,当分配虚拟内存时,内核先分配一个空闲地址区间,当cpu访问这个地址时,才分配实际物理页(真正使用的内存远小于实际分配的内存)。当cpu访问一个地址时,若发现当前地址未分配物理页,会触发page fault异常,在page fault异常处理中会给当前地址分配物理页,同时加载对应数据。第二个特点是按页分配,内核会以每次4kb为单位分配物理内存(内存页),为了减少内存分配的浪费。第三个特点是页表转换,在内存的申请/释放过程后,物理内存中会存在内存碎片,页表转换可以将不连续的物理内存映射到连续的虚拟内存地址。
虚拟内存不涉及实际物理内存分配,所以理论上虚拟内存应该是无限的,但是地址空间又受限于cpu的寻址能力,32位cpu寻址范围最大4G,所以32位设备虚拟内存上限也是4GB左右。虚拟内存不足会引发App OOM,进而引发App崩溃。而物理内存是内核管理的,当物理内存无法满足内存申请时,内核会进行内存回收动作,具体有释放缓存、压缩内存、后台杀进程等。内核在回收内存时会持有内存的大锁,所以如page fault等操作会卡住,导致整个用户空间的执行会非常缓慢,具体表现就是app卡顿/anr/闪退,但一般不会导致OOM,因为应用程序的内存需求是按页分配的,这算是一种最低的要求,内存总能满足,如果内存连一个物理页也提供不了,就表明系统其它重要的流程也无法执行了,就会触发内核的OOM,具体的表现就是手机的重启。
内存表示
| VSS | 虚拟内存大小 |
|---|---|
| RSS | 实际使用(独占+共享)物理内存大小 |
| PSS | Σ(独占物理页) + Σ(共享物理页/共享进程数) |
PSS越高 越容易在内核回收时被选中杀掉
内存的申请
1 | void* mmap(void* start, //起始地址,可以是空,也可以指定地址 |
- 文件映射
- flags未设置MAP_ANONYMOUS
- fd指向一个已经打开的文件
- 设备文件:dev
- 普通文件:system/data/vendor/sdcard
- 内存段名是文件路径
- 设备文件可以通过ioctl(ctl: control)修改内存段名
- 匿名映射
- flags设置MAP_ANONYMOUS
- fd一般为-1
- 内存段名默认为空
- 可通过prctl设置成
anon:xxx(Android10以后webview就是这样)
- 可通过prctl设置成
- 其他映射函数:mremap/munmap/mprotect/ioctl/prctl
内存分类分布与对应优化
内存分类与分布
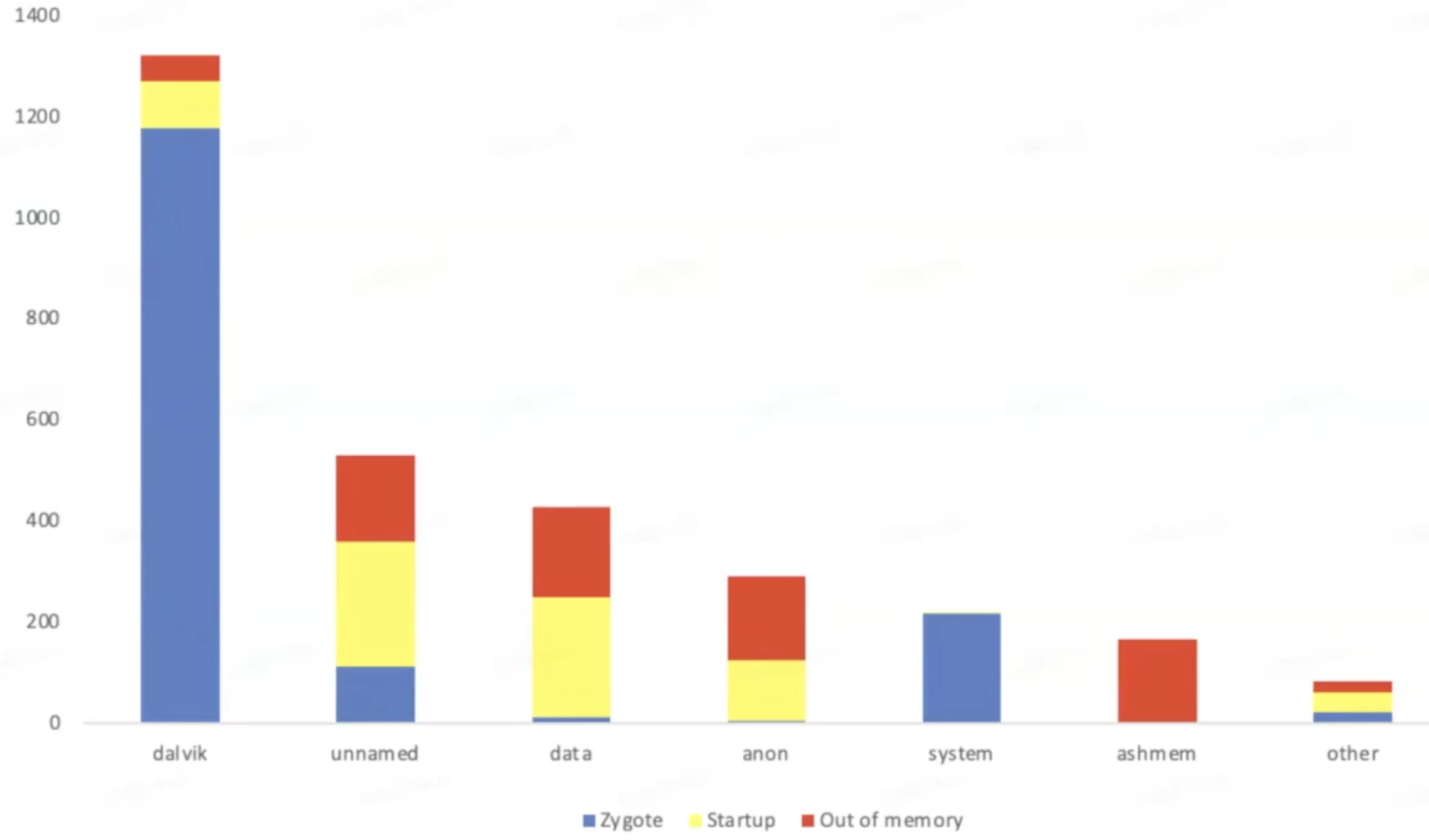
案例分析:32位设备运行32位app,总虚拟内存3G左右,从zygote到OOM这个过程中各阶段虚拟内存增量情况
注:
- zygoat:所有应用进程的父进程,app进程都由这个进程孵化而来)
- dalvik:dalvik虚拟机所占据内存
具体内存段的对应优化方案
虚拟机内存段

可以看出,内存消耗大头是mainspace、large object space和Bitmap,mainspace为什么有两个呢?这是虚拟机在内存碎片整理的时候所用(之前的博客里提到过),所以对应优化可以从这两块内存下手:
- Java堆裁剪:屏蔽内存碎片整理这个过程,将一块mainspace空间释放
- LargeObjectSpace
- Bitmap:Android8以上Bitmap在Native堆里分配内存,而不再在Java堆里分配内存,所以这也导致了Java OOM减少,而Native OOM增多
unnamed内存段
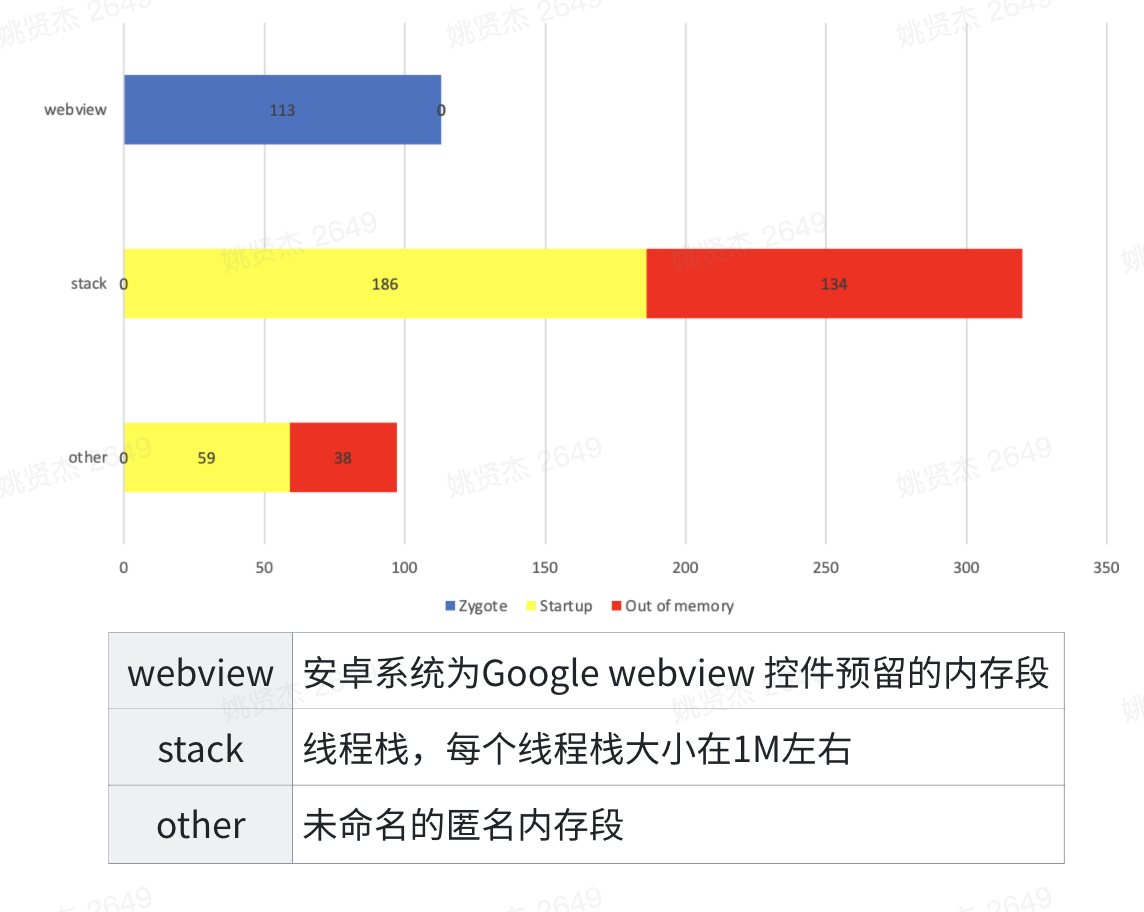
- webview:为了保证webview启动效率,Google在zygote阶段就给webview预留了一部分空间,但这部分空间不一定会被用到,而且现在很多公司自研浏览器内核,那这部分空间就是可以释放的(Android10 webview空间已经被命名了)
- 线程:一个线程占据1M,但通常用不到1M,可以hook Java线程创建函数然后裁剪Java线程栈,同时线程栈也会存在泄漏问题可以治理。
anon(已命名匿名内存段)
- libc_malloc:malloc/new申请的Native堆(占内存最多)
- 系统问题:jemalloc优化
- APP问题:堆内存泄漏监控(下文第三部分)
- .bss:so和dex文件的bss段
- thread*:栈保护页,信号栈
data内存段(文件映射)
和system区分,data是app自己的而system是系统的。
data目录下分data/app/和data/data,app目录下是so(动态库)、odex(字节码转换文件)等,优化空间较小,data目录下有plugins(插件)、webview等,如果下发插件比较多,plugins也占据很大。
system内存段(目录文件映射)
system目录下由四部分,so(动态库),ttf(字库),dat和other,其中字库占据内存但有可能利用率极低,也可以释放一部分。
ashmen内存段
Google为了解决多进程的内存共享而做的Linux里的驱动,路径信息基本无效,调用链都是系统库函数,很难对应具体业务,解决方案:hook(命名or记录),收集更多业务相关信息进行治理
other
一般是设备文件
堆内存泄漏检测原理
上一篇博客已经讲了内存泄漏检测的简单原理,这篇从代码角度加以阐述
系统malloc函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// @binoc/libc/binoc/malloc_debug_common.cpp
static const MallocDebug __libc_malloc_default_dispatch = {
Malloc(calloc),
Malloc(free),
Malloc(mallinfo),
Malloc(malloc),
Malloc(malloc_usable_size),
Malloc(memalign),
...
};
static const MallocDebug* __libc_malloc_dispatch = &__libc_malloc_default_dispatch;
extern "C" void* malloc(size_t bytes) {
return __libc_malloc_dispatch->malloc(bytes);
}
hook原理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static const MallocDebug s_proxy_dispatch = {
Proxy(calloc),
Proxy(free),
Proxy(mallinfo),
Proxy(malloc),
Proxy(malloc_usable_size),
Proxy(memalign),
...
}
static const MallocDebug* sDefaultDispatch = NULL;
void do_hook_malloc() {
void* handle = npth_dlopen("libc.so");
void* libc_malloc_dispatch = npth_dlsym_symtab(handle, "__libc_malloc_dispatch");
npth_dlclose(handle);
sDefaultDispatch = *(static const MallocDebug **)lib_malloc_dispatch;
*(static const MallocDebug **)libc_malloc_dispatch = &s_proxy_dispatch;
}
代理函数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18static void* proxy_malloc(size_t size)
{
void* raddr = __builtin_return_address(0);
void* faddr = __builtin_frame_address(0);
void* ptr = sDefaultDispatch->malloc(size); // 执行原malloc
push_mem(ptr, size, raddr, faddr); // 保存信息
return ptr;
}
static void* proxy_free(void* ptr)
{
pop_mem(ptr); //删除信息
sDefaultDispatch->free(ptr); // 执行原free
}
PS. 一般在分配的时候会获取当前的调用栈,但是调用栈获取可能很影响效率,所以这里获取函数返回地址和线程栈帧地址(都是从寄存器读,速度很快),返回地址可以定位函数,进而定位动态库,线程栈帧地址可以定位线程栈,进而定位线程。