前两天,看见公司有一些同学利用一些技术手段动态更新飞书签名,有人实时更新微博热搜,有人春节放假倒计时,还是挺有趣的,正巧北京这几天疫情比较紧张,我就也写了一个服务在飞书签名上定时更新北京的风险地区。
梳理了一下步骤流程,首先获取到飞书的cookie,然后在字节的“轻服务”平台上线一个服务,用来利用cookie更新飞书签名,接着在开发机部署一个定时任务,定时在丁香园爬取北京的风险地区,然后将数据post到刚刚上线的轻服务上,数据打过去之后,轻服务就能更新签名了。至于为什么用轻服务而不在开发机走完整个流程,因为cookie里的信息比较重要,放在开发机不够安全。
获取cookie
登录飞书网页版,对任意飞书api请求均可,复制cookie

在轻服务平台创建轻函数并上线
1 | module.exports = async function(params, context) { |
在开发机部署定时爬虫任务
1 | import json |
在后台不挂起执行1
nohup python3 crawl.py &
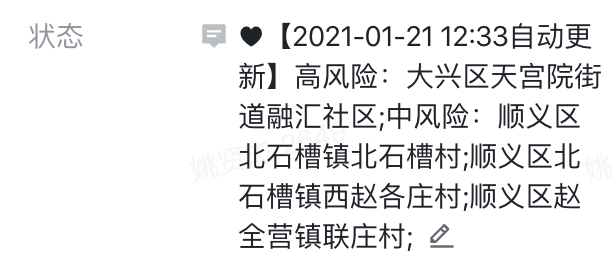
最终效果